Elaborate Engineering with Neverinstall: Reactive and pre-emptive scaling
Learn how we scale the platform to deliver unparalleled performance to more than 250,000 users on Neverinstall.


Scale for power
We are a large software-driven world, dependent on complex pieces of code to make myriad tasks easier – and in a lot of cases possibly, which would otherwise be not. However, we need hardware (or machines) to run our software. Our hardware, composed of the necessary components, offers the necessary power and resources to execute the code of our software and, thus, yield desired results. These resources, which include compute, RAM, storage space, bandwidth, and more, are the fuel required to support our software as we hope to use them. However, like most others on our planet, these resources are limited – requiring scale to achieve more.
A limit to the escape
Traditionally, our machines are horizontally scalable, i.e. we can achieve more power by simply having more machines. In our case, we need more power to support more users on the platform to deliver a consistent user experience; and prevent system failures.
However, it is virtually impossible to keep a huge number of machines running at all times. We need to consider, that computing requirements keep changing throughout the day – as the number of users on the platform increases or decreases, we need to adjust the delivery of computing power to the platform to optimize for costs, performance, and sustainability.
What it means for us
The power available to us directly affects the time it takes to create a user application/container. Since we require hardware on our end to set up the applications for users on the platform, as the number of users increases we need more machines ready to go to support them and need to turn off machines to contain costs.
Any Space that a user creates on the platform is a combination of 3 containers clubbed together and run as a ‘Pod’ in Kubernetes. The Pods are then run on worker Nodes which is the ‘machine’ that we scale up or down depending on user traffic. So, we need to decide the number of worker Nodes running at any point in time while optimizing for cost and user coverage.
What we need as a platform is an intelligent solution to scale up and scale down our systems intelligently to accommodate and cater to fluctuating user traffic; where we need to push for more power during peaks and prevent the disuse of resources during troughs.
And this is how we do it! (insert a Montell Jordan voiceover)
Comprehending demand and supply - scaling up and down
When we discuss scaling, we look at it from both perspectives – scaling up and scaling down. And, to understand scale, we need to consider the following three scenarios:
Stasis
If the desired number of Nodes matches the existing number of Nodes, it means that the platform has adequate to serve all users. Therefore, no action is needed.
Scaling up
- If the desired number of Nodes is greater than the existing number of Nodes, we need to scale up and provide the desired number of Nodes to the Kubernetes cluster in each region. Once the Nodes are added, the cluster takes care of provisioning and readying the new machine at some future point in time.
Scaling down
- If the desired number of Nodes is lower than the existing number of Nodes, then we need to scale down takes place. This is where it gets a little tricky.
We use DaemonSets that run in the clusters to cache container images on the Node – it ensures that (all or some) Nodes run a copy of the Pod. As and when Nodes are added to the cluster, DaemonSets ensure Pods are added with them. However, this process takes some time. Therefore, while scaling down, turning a blind eye to the work done by these caching mechanisms and deleting any Node at random would be sub-optimal.
Consider this, if there are two machines (A and B) and the work done on them is X and Y respectively (where X>Y), then it would be better to delete machine B rather than deleting machine A or deleting them at random. We need to preserve the work already done on machine A to ensure optimal performance and provisioning.
To solve this, we first sort the machines based on the work done by the DaemonSets – which is essentially the running time of the said DaemonSets and then delete the Nodes with the least running time completed from the Node pool in all the clusters.
Understanding scaling
There are two ways to scale machines to cater to a changing requirement of resources:
Reactive Scaling
Reactive scaling allows us to scale up or down the machines as and when the user traffic increases or decreases. At Neverinstall, we have been using reactive scaling since we started developing the platform since it was one of the fastest possible solutions at that time.
We regularly checked the demand for Spaces and on the other end, we checked how many machines were currently running. Depending on the demand-supply curve we scaled up or scaled down the machines to maintain equilibrium throughout the platform.
The algorithm looked something like this:

Drawbacks of a reactive system
Although reactive scaling allowed us to deploy scaling measures immediately to the platform, it was a reasonably straightforward solution, and with drawbacks.
- First off, the machines required some time before they were set up and recognized by the Kubernetes controllers. Typically, it would take 10 to 12 minutes to set up a machine, and until that time the user Pod cannot be set up. Simply put, let's say a user comes and requests an application, and we don't have enough machines at that time to service the user, then that user cannot be served until a new machine is completely set up or some other user pauses/deletes their Space.
- Second, a reactive scaling algorithm becomes detrimental to the platform during events of occasional user traffic spikes. Since machines take time to set up, there is a gap between user traffic increasing and it being served. However, there are times when the user traffic spikes are short-lived. Therefore, in these cases, the spike may end even before machines are used, and the provisioning of machines is wasted.
- Most cloud providers have a granularity of calculation of usage time in Hours. However, most machines (due to reactive scaling) are provisioned for less than an hour and deleted afterward. This way the number of unique machines that are provisioned skyrockets and as a result bills are raised for cloud costs for a whole hour. To put this into some perspective, if one machine ran for half an hour and another for another half hour, the platform will be billed for two machines (one hour per machine) which is eventually worse than keeping a single machine running for a full hour.
Pre-emptive scaling
As the platform evolved, we sought a better solution to optimize performance without raising costs. We needed to anticipate demand on the platform and have machines ready to go before users would appear on the platform. Therefore, we deployed pre-emptive solutions on the platform to scale the machines earlier on by learning from the trends and patterns of the historical user traffic data.
Essentially, we studied historical data of our users' usage information and deployed the algorithm to decide how many machines will the platform need at some point of time in the future. This information is then used to scale up/scale down the machines based on that well in advance of user traffic peaking or falling.
The algorithm looks something like this:
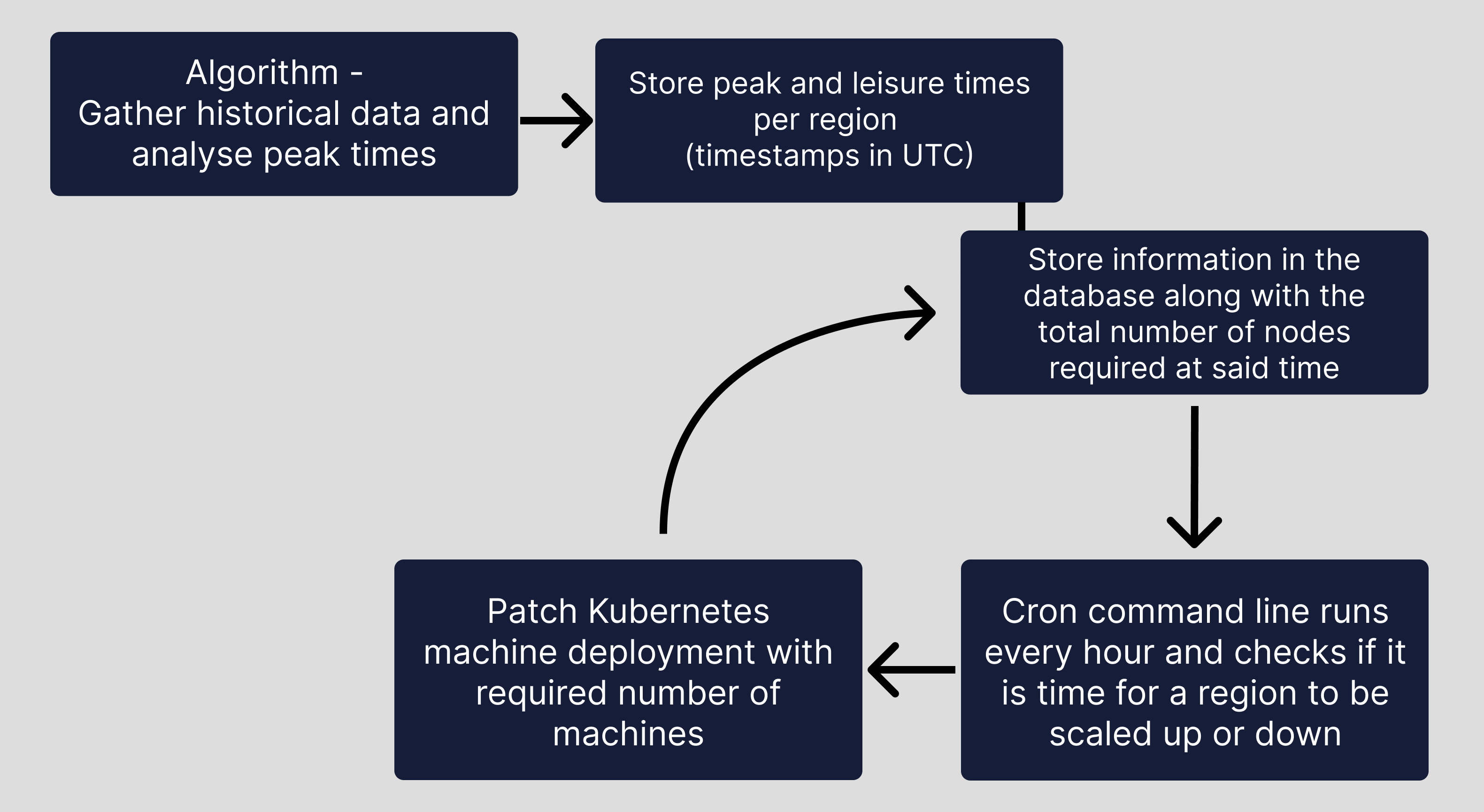
Keep in mind
We noted that the usage patterns can change over time and it gets difficult to continuously keep the algorithm/parameters updated. And although the approach enables better provisioning of machines – it is not perfect.
Further, we need to keep note of the fact that pre-emptive scaling does not protect us from unexpected spikes or dips in usage requirements and it can lead to unexpected over-provisioning or under-provisioning of resources if not monitored properly.
Our way forward
What we realized was that with over 250,000 users on the platform we need a mix of different approaches to deliver the best results. Coupled with this, we monitor our systems regularly to ensure optimal provisioning and maintaining resources required to maintain optimal performance.
Create a Space on Neverinstall and experience unparalleled computing performance. Sign up today!